
A few weeks ago Adobe added new Speech to Text features to their latest release of their Creative Cloud app, Premiere Pro.
Many of you may have experience with some of the other AI based transcription services out there such as Trint or Rev, but the big advantage that Adobe’s option has is that they have made it free to Creative Cloud users.
Backed by the Adobe Sensei machine learning architecture, Adobe is positioning Speech to Text as a free and accurate option for generating transcripts and captions.
While our post house is primarily Avid Media Composer based, many of our casting and series development teams use Adobe Premiere to cut their casting and pitch videos. Typically, these projects are low budget and/or time sensitive, and do not have the option of sending out videos to traditional transcription venders.
When using the Speech to Text functionality to transcript your videos, Premiere uploads the audio files to Adobe’s servers (which Adobe promises are GDPR compliant for our EU friends), converts the files to a text transcript, and allows you to then generate subtitles and captions all within Premiere.
In our experiments, exporting, uploading, processing, and then receiving a transcript for an hour long video took approximately 30-40 minutes depending on the number of speakers, and the number of audio tracks in the video segment. Comparing that to 12-24 hour turnaround for a traditional transcription workflow, this is a big time and budget saver for these smaller projects.
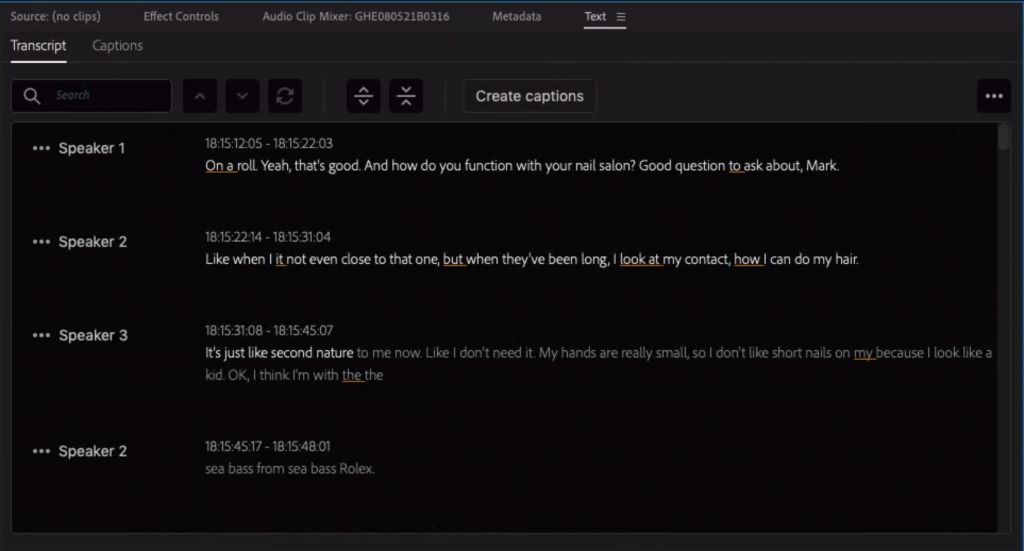
Currently, Adobe supports exporting the transcripts to plain text files and to a variety of caption formats. For a complete list, you can view their article on Supported File Formats.
File export formatting is also the biggest opportunity of improvement for the Speech to Text function. Unfortunately, when exporting to plain text multi-speaker data and source timecode information are not included. Multi-speaker data also is not included in the caption export files and the timecode that is included in these files do not match the sequence timecode from Premiere, but are rather run-time timecode. This multi speaker and timecode metadata is currently only visible inside Premiere itself.
The plain text transcript exports are fully ScriptSync capable if you have ScriptSync for Avid. So if you have a mix and match of Avid and Adobe editors in your environment and need a quick set of transcripts for your Avid team, Premiere can also help you out here.
The new Speech to Text functionality from Adobe is a great addition for Premiere Pro editors. It has a good accuracy, is relatively fast to generate transcripts and captions with, and the fact that it is included free of charge for Creative Cloud users makes it a financially friendly option for those on smaller projects or tight deadlines. I do not see it replacing traditional transcription options for larger projects without adding a few more features and including timecode and speaker names in the text file exports, but it is definitely a contender in the AI transcription workspace.
Stay tuned for my How To Use Adobe’s Speech To Text post.

As an Amazon Associate, Nerdypup.com may earn a small commission from qualifying purchases.